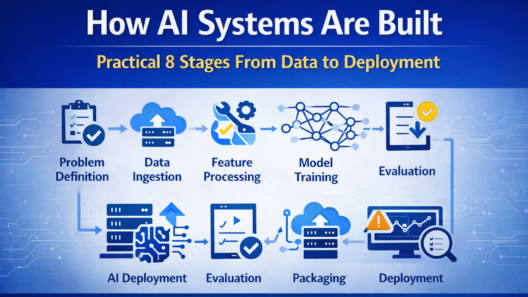
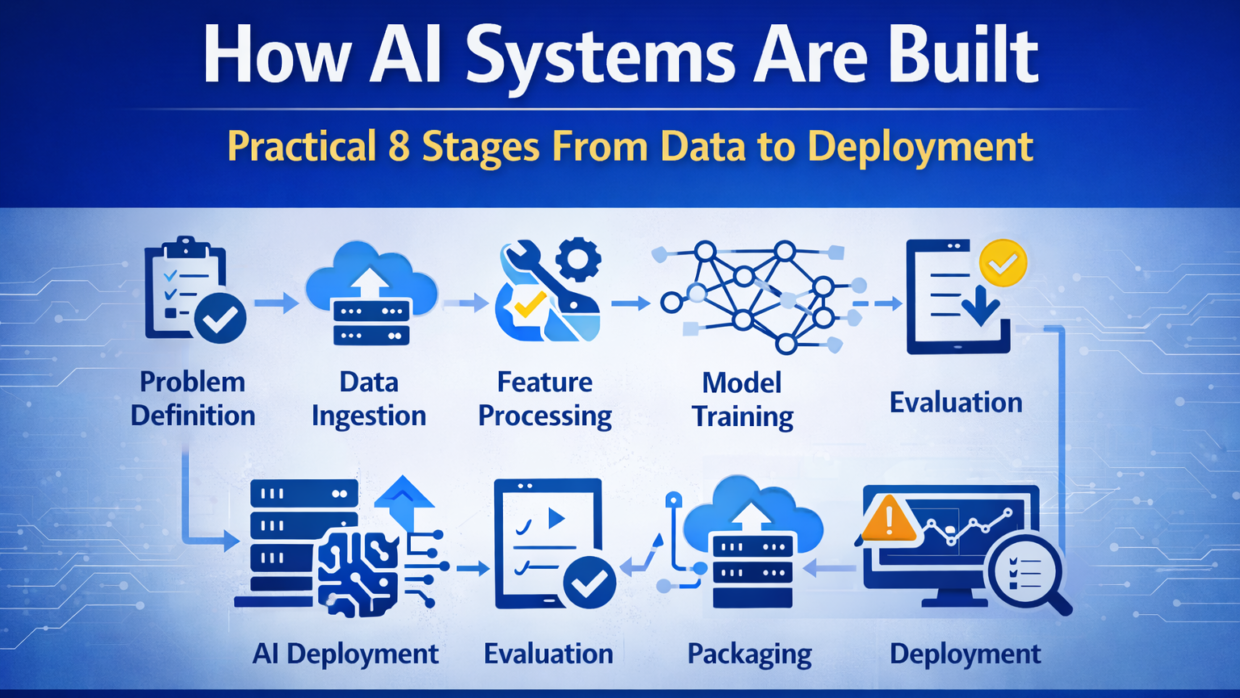
Modern AI systems are not created by training a model and deploying it once. They are end-to-end systems that combine data pipelines, models, infrastructure, and monitoring into a continuous lifecycle.
This guide explains how AI systems are built from data to deployment, focusing on the practical steps and engineering decisions involved in moving AI from experimentation into reliable production systems.
Table of Contents
Understanding AI Systems as End-to-End Pipelines
An AI system is more than a model. It is a pipeline that transforms raw data into predictions or actions that power real applications. 
A complete AI system typically includes:
- Data collection and validation
- Feature processing
- Model training and evaluation
- Deployment and inference
- Monitoring and continuous improvement
Each stage depends on the others. Weakness in one stage affects the entire system.
Step 1: Problem Definition and System Requirements
Every AI system starts with a clearly defined problem.
Before touching data or models, teams must answer:
- What decision or task should the system support?
- What level of accuracy is acceptable?
- What latency and cost constraints exist?
- How will success be measured in production?
Clear requirements prevent overengineering and ensure the system is aligned with real business or user needs.
Step 2: Data Collection and Ingestion
Data is the foundation of AI systems.
AI engineers design ingestion pipelines that:
- Pull data from databases, APIs, logs, or sensors
- Handle structured and unstructured formats
- Validate schemas and data quality
- Track data sources and versions
Reliable ingestion ensures that downstream models receive consistent and trustworthy inputs.
Step 3: Data Cleaning and Feature Processing
Raw data is rarely usable in its original form.
This stage focuses on:
- Removing duplicates and invalid records
- Handling missing or inconsistent values
- Normalizing and transforming data
- Creating features that models can learn from
Feature processing must be reproducible, so the same transformations apply during both training and inference.
Step 4: Model Selection and Training
With prepared data, teams select and train models.
Key considerations include:
- Model complexity versus interpretability
- Training cost and time
- Inference latency requirements
- Ease of deployment and scaling
In production systems, the best model is often the one that balances performance, reliability, and operational cost.
Step 5: Evaluation and Validation
Offline accuracy alone is not enough.
Evaluation includes:
- Validation on unseen data
- Stress testing edge cases
- Measuring bias and fairness risks
- Simulating real-world conditions
This step ensures the model behaves predictably before deployment.
Step 6: Packaging Models for Deployment
Once validated, models must be packaged for use in applications.
Common approaches include:
- Containerized model services
- Serverless inference endpoints
- Embedded models within applications
Packaging decisions affect scalability, latency, and maintenance complexity.
Step 7: Deployment and Inference
Deployment is where AI systems encounter real-world conditions.
Key deployment concerns:
- Real-time vs batch inference
- Autoscaling under variable load
- Failover and rollback strategies
- Hardware selection (CPU vs GPU)
A well-designed deployment minimizes downtime and unexpected failures.
Step 8: Monitoring and Feedback Loops
AI systems change over time as data and user behavior evolve.
Monitoring focuses on:
- Prediction quality and drift
- Data distribution changes
- System latency and error rates
- Cost and resource usage
Feedback loops allow teams to retrain models and update systems proactively.
The Continuous AI System Lifecycle
AI systems are never “finished.”
A typical lifecycle looks like:
- Collect new data
- Retrain or update models
- Validate performance
- Redeploy safely
- Monitor continuously
This cycle repeats as long as the system is in use.
Common Challenges When Building AI Systems
AI systems introduce challenges beyond traditional software.
Data Drift
Real-world data changes over time, reducing model accuracy.
Hidden Dependencies
Small upstream data changes can cause downstream failures.
Operational Complexity
AI adds new infrastructure, monitoring, and cost considerations.
Debugging Difficulty
Failures may originate from data, models, or infrastructure layers.
AI engineering practices exist to manage these risks.
How This Fits into AI Engineering Fundamentals
This article expands on the concepts introduced in
AI Engineering Fundamentals, showing how theory translates into real systems.
Together, these guides explain:
- What AI engineering is
- How AI systems are built
- Why system thinking is essential for reliable AI
Future articles will explore models, infrastructure, deployment, and monitoring in more depth.
Conclusion
Building AI systems is a system engineering challenge, not just a modeling task. Success depends on how well data, models, infrastructure, and monitoring work together across the full lifecycle.
Understanding how AI systems are built—from data to deployment—provides the foundation for creating AI solutions that are reliable, scalable, and trustworthy in production environments.
Frequently Asked Questions
What is an AI system?
An AI system is an end-to-end pipeline that uses data, models, and infrastructure to produce predictions or decisions in real-world applications.
Is model training the most important part of an AI system?
No. While important, deployment, monitoring, and data quality often have a greater impact on real-world performance.
Why do AI systems fail in production?
Common causes include data drift, poor monitoring, unrealistic assumptions, and lack of operational safeguards.
How often should AI systems be updated?
AI systems should be updated whenever data changes significantly or performance degrades in production.
💬 Community Question
Which stage of building AI systems do you find most challenging: data, training, deployment, or monitoring?






{kind=link}